Results
What we found out
The initial overall accuracy of the classification method trained with R, evaluated using a test set of 300 points, is 0.70, as depicted in the error matrix.

Accuracy Improvement
We thought about how to increase the accuracy of the model, taking into consideration the computational limits of our machine. Expanding the dataset size by a factor of four (from 700 to 2800 points) did not yield a notable increase in the overall accuracy. Surprisingly, the accuracy experienced a slight decline from 70% to 69%. However, upon incorporating 10000 points, a significant improvement in accuracy was observed, reaching 79%. Due to computational limitations, we refrained from further increasing the number of data points.
Landslide Susceptibility Map
Following the evaluation, we have acquired an error matrix that reveals a precision index value of 0.79. This value, obtained after assessing the accuracy improvement, signifies a sufficiently high level of reliability in the results of the susceptibility map.

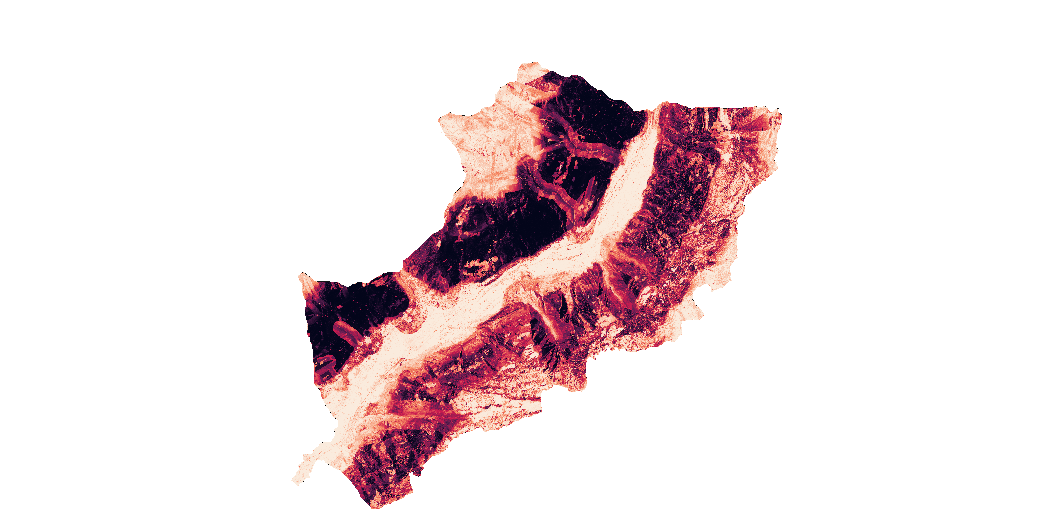
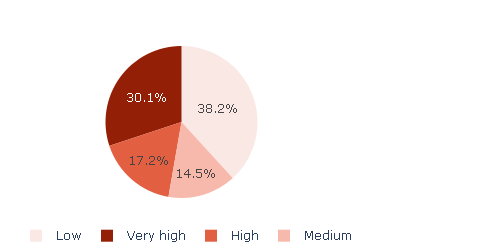
Population Exposure Assessment
The analysis performed reveals the total area characterized by a significant risk of landslides cannot be disregarded. Despite a considerable portion of the population residing in safer regions, a substantial segment remains vulnerable to an extremely high risk of landslides.
Errors handling
Below we illustrate the main errors we encountered during the implementation of the model.
- Fitting the correct spatial extent to the environmental factor layers and the correct pixels size
It happened that by adjusting one of these two values, the other changed accordingly in worse. Also, trying to apply a pixels size smaller than the threshold size is certainly not possible, so to solve the problem we recreated the layer starting from the initial one. We realized later that inserting the appropriate pixelsd size, was not sufficent, it was also necessary to activate a check box that did not jump out at us at first. This led to a projfix() error message that states that the predictor layer rasters are too different to reconcile. The algorithm attempted to reconcile the predictor layer rasters but failed. - Wrong input names
we realized after several attempts that the names of the files containing the environmental factors and the training/testing points had to be necessarily those suggested by R ModelMap, although it was possible to select them manually. Also within the folder containing the environmental factors it was better not to have any files other than the necessary ones (not even the temporary layer files used), as it was not possible to indicate a working folder for the model output that was not empty.This led to a model.explore() error message that states that the predictors "aspect," "dtm," "ndvi," "rivers," "faults," "dusaf," "roads," "plan," and "profile" from 'predList' were not found in 'qdata.trainingfn'.